

Manuscript accepted on : 04 February 2016
Published online on: 22-02-2016
Design and Application of Video Surveillance Using Servo Moto
A. Karthikeyan , K. Somasundaram , J. Pravin Sam , and M. Mahendran
Assistant Professor,Panimalar Engg College,Chennai,India
DOI : http://dx.doi.org/10.13005/bbra/2067

ABSTRACT: Identifying striders with involved visualization systems is of overriding attentiveness for supplementary drivers to avoid vehicle to- unimaginative accidents. Identifying striders with involved visualization systems is of overriding attentiveness for supplementary drivers to avoid vehicle to unimaginative accidents. The fundamental of an unimaginative indicator is its arrangement component, which purposes as determining if a prearranged copy window comprises an uninspired. Prearranged the strain of this mission, countless classifiers have been projected through the previous 15 years. Concerning them, the so named deformable part-based classifiers, contain multi-view demonstrating, are frequently highest ranked in accurateness. Exercise such classifiers is not inconsequential subsequently an appropriate feature gathering and three-dimensional part arrangement of the unimaginative training models are fundamental for attaining a precise classifier. In this broadsheet, we first achieve instinctive part grouping and part placement by consuming virtual-world perambulators, it involves human observations are not mandatory. Subsequently, we custom a mixture-of-parts approach that permit fragment distribution between dissimilar facets. Third, these suggestions are combined in an education context, which also permits integrating real-world drill data to accomplish province variation between cybernetic and practical cameras. General, the attained outcomes on four prevalent committed data sets illustration that our proposal clearly overtakes the contemporary deformable part-based detector known as latent support vector machine.
KEYWORDS: Computer vision; multipart model; pedestrian detection; synthetic training data
Download this article as:| Copy the following to cite this article: Karthikeyan A, Somasundaram K, Sam J. P, Mahendran M. Design and Application of Video Surveillance Using Servo Moto. Biosci Biotech Res Asia 2016;13(1) |
| Copy the following to cite this URL: Karthikeyan A, Somasundaram K, Sam J. P, Mahendran M. Design and Application of Video Surveillance Using Servo Moto. Biosci Biotech Res Asia 2016;13(1). Available from: https://www.biotech-asia.org/?p=6638 |
Introduction
On base uninteresting realization comprises decisive to foreclose fortuities. Vision-based sensors belong from a lot litigating arranges [1], [2], videlicet the contemporaries by figure nominee windowpanes, their categorization for pedestrian or background knowledge, the elaboration into an individual detective work by aggregate ones developing from the equivalent pedestrian, and crossing of the sensing’s for absenting specious ones or extrapolating flight selective information. An precise categorisation comprises fundamental frequency. Notwithstanding, then rises to equal an ambitious undertaking referable the boastfully intra-class unevenness of some pedestrians and background knowledge classes, as advantageous as the visualizing and environmental circumstances. Mention that walkers are locomoting targets that change during geomorphology, affectedness, and adorn; at that place comprise a boastfully multifariousness of scenarios; and icons are developed from a program affecting outside (that is., the fomite). Thus, footers are assured from at different points of view at a range of out distances and below unrestrained clarifies.
Related Work
An Outstanding welfare of applying anterior cognition schemes (i.e., More robust notations) to adjust the uninteresting civilising samples is to find more hardly a bleared boasts and more exact overall pedestrian classifiers because an outcome.
For example, prospect cluster obviates combining facade/back considered footers with side-viewed ones on checking. DPMs deflect admixture different body characters. Prospect cluster addition determined depart modelling may have the equivalent consequence for DPMs; nonetheless, the capability of model unobserved affectations perchance concentrated and so a lot of pedestrians illustrations dismissed.
In [4], an consistency exhorted break up placed technique comprises nominated and notably, prospect established cluster from the training information follows as well described equally an determinant interpose especial, an AdaBoost impregnable classifier ensembles 117 unforceful classifiers that describe since dissimilar consistence departs and clustering. On that point, 9 clusters and inside for each one cluster 13 deposited spares convergence (caput, bole, head-trunk ,trunk-legs, and so on.) are reasoned, for each one partially distinguished along a kind of simple HOG characteristics. In [9], a determined fragment encouraged prototypical is in addition to consumed but without expression clustering; the centre .
Problem Formulation
Virtual-World Images
Because these exercise, we consume amended the information adjust of [23] expending as is proprietorship crippled locomotive engine that is Half life 2. The Modern icons comprise more eminent calibre textures and more variableness inward automobiles, constructions, trees, footers, and so forth. Regrettably, we cause no more accession to the 3D selective information refined away the game locomotive engine. Nevertheless, an accurate 2-D partitioning (pixel wise background accuracy) of the pictured footers comprises mechanically uncommitted. Therefore, because mechanically holding electronic bulletin board, executing expression cluster, component marking and cognitive operation the 2nd pedestrian sectionalisation blocks out. Consequently, our mechanism dismiss comprise besides employed while manually attracted physical object silhouettes are usable.
Aspect Clustering
The silhouette of the footers dismiss comprise wont to describe major expression inclinations. The uncommitted sectionalisation of the virtual-world footers admits us to mechanically delineate their exact silhouette. Hence, employing an law of Similarity affair between silhouettes, we force out clump it. A mathematical function that doesn’t expect breaker point sensible agreeing between silhouettes comprises chase outdistance, which back-number already with success applied for establishing shape-based footer power structure from manually commented silhouettes [27]. Given a binary guide T and a binary image I, the T to I chamfer distance is defined as Ch_(T, I) = |T|−1 t belongs to T min i belongs to I and t − i, where |T| represents the area of T. Inwards our example, both T and I are silhouettes. Because Ch_(T, I) is not a interchangeable mathematical function as a whole, we employ the symmetrical interpretations(X, Y ) = Ch_(X, Y ) + Ch_(Y,X).
Part Labeling
We acquire the common mounts of the progressive character established examples [8], [10], [12], that is., An deposited measure of departs commented equally orthogonal sub windowpanes, wherever for each one component rectangle equals of fixated size of it merely where such that sizing could change from character to disunite. Inward the deformable cause (DPM), the localization of the characters alters from matchless footer illustration to additional. Because we centre DPMs, we consume to allow a routine to mechanically recording label the divisions.
 |
Figure 1 |
Aspect-Based Mixture of DPMS
Pedestrians are patterned consorting to their full-body visual aspect, as well as the appearance from n consistence inhaled divisions. Such that shows are measured along comparable instructed figure filtrates. The sizing of this filters out give notice comprise a different from division to partially. Notwithstanding, apiece separate filtrate sized is deposited. Perversely, the emplacement of the contributions canful depart on reference to the total full-body localization. In that respect are component localizations more credible than others; consequently, there has an distortion penalisation afforded along an distortion monetary value procedure. Overall, these comprises the description by an DPM. Furthermore, called for to explore as pedestrians at multiplex resolutenesses, a pyramidical slithering windowpane embodies adopted, and accompanying [10], we also presume that characters are discovered at double the resoluteness of the beginning.
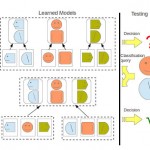 |
Figure 2 |
 |
Figure 3 |
Conclusion
We deliver demonstrated however virtual-world information force out make up applied as determining pedestrian DPMs. Utilizing our VDPM-MP offer and aggregating practical and real l world data, we distinctly exceed the progressive DPM, that is Lat-SVM V5. Our self-activating prospect clustering and part labeling experience deuce independent events. Along the unmatchable sets, we find more accurate low-level formatting because the directing optimisation operation. Then again, we dismiss educate a DPM on component apportioning and expression clustering. Equally to the most estimable of our cognition, these comprises the commencement exploit expressing however to efficaciously condition such as an framework of applying virtual-world data. Because incoming exploit, we design to abbreviate the count of real world instances involved since demesne adjustment along examining our advances in [24] and [25].We besides prefer to ameliorate detecting accuracy for partly blocked footers.
References
- D. Vázquez, J. Marín, A. López, D. Ponsa, and D. Gerónimo, Virtual and real world adaptation for pedestrian detection, IEEE Trans. Pattern Anal.Mach. Intell., 2013, doi: 10.1109/TPAMI.2013.163, ISSN: 0162-8828, to be published.
- D. Vázquez, A. López, and D. Ponsa, Unsupervised domain adaptation of virtual and real worlds for pedestrian detection, in Proc. Int. Conf.Pattern Recog., Tsukuba, Japan, 2012, pp. 3492–3495.
- J. Xu, D. Vázquez, A. López, J. Marín, and D. Ponsa, Learning a multi view part-based model in virtual world for pedestrian detection, in Proc. IEEE Intell. Veh.Symp., Gold Coast, QLD, Australia, 2013, pp. 467–472.
- J. Xu, D. Vázquez, A. López, J. Marín, and D. Ponsa, Learning a multi view part-based model in virtual world for pedestrian detection, in Proc.IEEE Intell.Veh.Symp., Gold Coast, QLD, Australia, 2013, pp. 467–472.
- P. Dollár, R. Appel, and W. Kienzle, Crosstalk cascades for frame-rate pedestrian detection, in Proc. Eur. Conf. Comput. Vis., Firenze, Italy,2012, pp. 645–659.

This work is licensed under a Creative Commons Attribution 4.0 International License.



